Web applications typically feed information back and forth from a database to process information for the user. Organizations need to build applications that can scale with their business. While it is easy to scale web applications with containers and cloud platforms, the last thing that an IT administrator would want is a bottleneck at the database because it would affect application performance and availability at scale. One way to address these concerns is by using a clustered database solution such as ScyllaDB. This blog post will demonstrate how to use Node.js and ScyllaDB running in Docker.
Category Archives: Uncategorized
Introducing Cloud Explorer 10
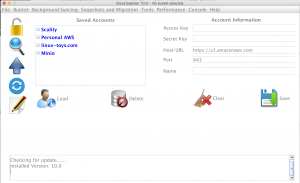
Cloud Explorer is a powerful GUI and CLI Amazon S3 client. In this release there is many code improvements to help users sync their data to a S3 bucket and migrate data between different S3 providers. There is also better support for S3 compatible servers such as Scality S3 Server and Minio.
Syncing, bucket migrations, and snapshots were completely rewritten for optimal performance. Now five sync tasks can run at the same time. Each task will check the file metadata and perform the necessary upload and download operations concurrently instead of a single operation at a time.
The Background sync feature enables users to perform a bidirectional sync on a folder like Dropbox in the GUI or CLI every five minutes. This feature was also rewritten and takes advantage of the improved syncing algorithms discussed earlier. Since it now runs in it’s own thread with a separate configuration file, users can use Cloud Explorer while the sync tasks run in the background.
Path Style access is now enabled for non-aws accounts providing better support for private S3 compatible servers like Scality and Minio. Users will now also be able to connect to these servers by IP address or DNS.
Regions have been removed from the code and configuration file. Cloud Explorer will retrieve the appropriate region from the S3 account resulting in better functionality and easier use. This being said, that means that previous Cloud Explorer configuration files will not work in the new release and the accounts will have to be added again.
The CLI now supports bucket snapshots and migrations with the ability to use environment variables instead of a configuration file. This functionality makes it easier to run in a container such as Docker or Rocket.
I hope that you will enjoy this exciting new release and please provide feedback on the GitHub or directly to me on .
PiCluster 1.7 – Efficient Container Management
I am pleased to announce v1.7. In this release, I wanted to make PiCluster easier to use by having the Web Console handle most of the common configuration file changes. Not everyone enjoys editing json files including myself. Now let’s go over what is new in this release.
Continue reading PiCluster 1.7 – Efficient Container Management
How to use Cloud Explorer with Minio
I did some updating to recently to make it work with Minio. Minio is one of many open source S3 servers available today for people to use on-premises for their personal cloud storage needs. With the added support, Minio users can take advantage of Cloud Explorer’s unique features such as performance testing, note taking, playing music, viewing images, and search.
Continue reading How to use Cloud Explorer with Minio
PiCluster 1.6 – Move your Containers to Different Hosts
I am pleased to announce v1.6 of . In this release there are a few usability bugs fixed and a new feature that allows you to change the host of a running container. Having the ability to easily change where a container is running is a standard and crucial feature to expect from a container management platform. I am glad that it is finally here and let’s explore how it works!
Continue reading PiCluster 1.6 – Move your Containers to Different Hosts
Announcing PiCluster 1.4
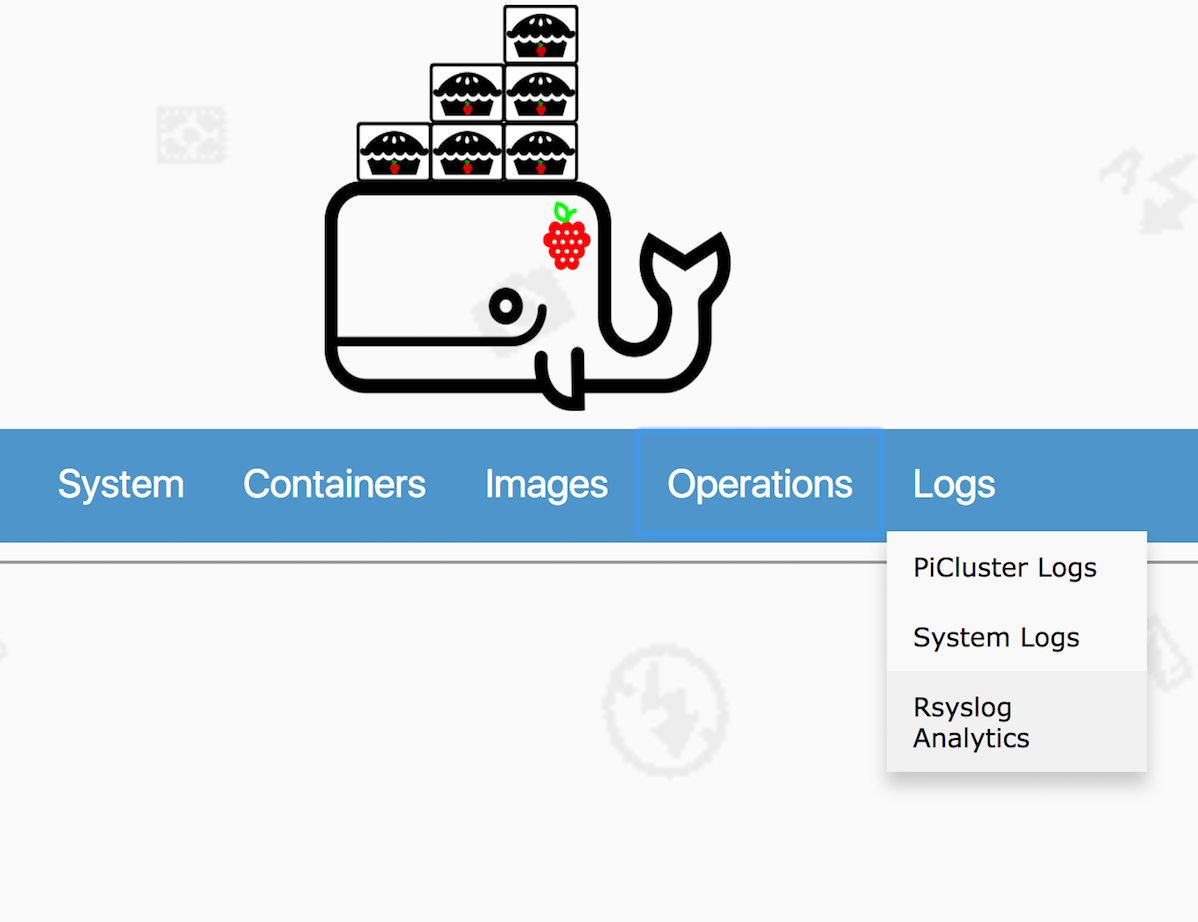
I am pleased to announce the new version of . In this release, users can connect to a host running an rsyslog server and the PiCluster agent to view the log drain in the PiCluster web console and run searches. This combined integration provides a single pane of glass to monitor physical hosts and Docker containers easily. Let’s take a look on how to enable this functionality.
Continue reading Announcing PiCluster 1.4
Thanks for the support in 2016

Most people will say that 2016 was a terrible year and can’t wait for 2017. I agree that 2016 was not perfect for many people but it was a great year for linux-toys. I made this blog with the goal to influence people and drive that creative spark that we all have inside. In this blog post I will go over the website statistics and discuss a few of the blog entries that I thought were most influential for the year.
My Journey to Improve Disk Performance on the Raspberry Pi

I switched to Gluster FS a while ago to provide easier container mobility across my Raspberry Pi Docker Cluster. Gluster worked great and was easy to get up and running but I had very poor performance. The average write speed was about 1 MB/s which is unacceptable for a filesystem that will undergo a lot of writes. I decided that it was time to take action and started looking at kernel parameters that could be changed.
Continue reading My Journey to Improve Disk Performance on the Raspberry Pi
Using PiCluster to run Scality S3
I released last week and wanted to show how to run the S3 server with it using Docker. Scality S3 is an open-source object storage server. PiCluster is a simple and lightweight container management and orchestration framework that I wrote in Node.js. Besides running containers, PiCluster can also perform health checks on applications to ensure that a service is actually running. Before we begin, I am assuming that you already have Docker installed. Lets get started by downloading PiCluster.
Continue reading Using PiCluster to run Scality S3
Running a Gluster Cluster on the Raspberry Pi with Docker
I was always fascinated with distributed filesystems and wanted to learn more about Gluster since it is becoming more popular in larger open-source projects. Since I have a few Raspberry Pi’s, I thought that now is the best time to learn. This blog post will explain how to run Gluster on a two-node Raspberry Pi cluster from a Docker container.
Architecture
- Two Raspberry Pi’s (rpi-1 and rpi-2)
- Running a Gluster image from a local Docker registry
- Hostnames are resolvable in /etc/hosts on both Pi’s
- Docker 1.12.x installed
Continue reading Running a Gluster Cluster on the Raspberry Pi with Docker